Was Your Music Used to Train AI? Now You Can Actually Find Out.
The Atlantic just made 21 million scraped songs searchable. Here’s what we found.
Go to theatlantic.com. Pull up the AI Watchdog tool. Type your artist name.
If you’ve put music on YouTube, SoundCloud, Spotify, or anywhere else in the last decade, there’s a real chance you’re about to see your own catalog staring back at you inside a database you never signed off on.
That’s what happened to SZA on June 21, 2026. The Grammy-winning singer searched her name and found 238 of her songs listed in an AI music training database — including what she believed were unreleased tracks. She went straight to Instagram: “If your a musician and you support this degenerate shit? Your disgusting and there’s NOTHING YOU COULD EVER SAY TO ME TO MAKE THIS OKAY.”

We ran some of our own searches through the Atlantic tool, checking independent and underground Hip Hop artists, and almost no one came up clean. DJ JS-1 had 31 results across two datasets. Ruste Juxx had 121 results across two datasets. Homeboy Sandman was hit for 273 results. Even Jay Smooth — better known as a journalist, podcaster, and YouTube personality than a recording artist — had videos and content scraped into the mix. Underground, independent, major, famous, obscure: the scraper didn’t discriminate. If it was out there, it got collected.
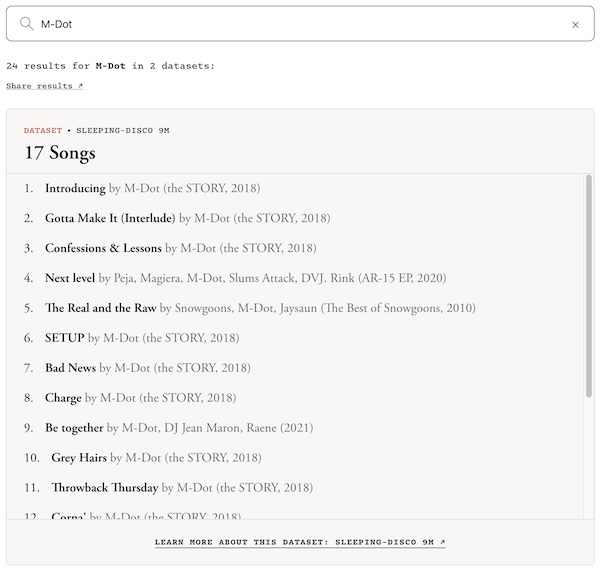
What changed? A journalist named Alex Reisner at The Atlantic found four massive databases that had been quietly circulating through the AI development community for years — containing over 21 million recordings combined — and made them fully searchable for the first time. The receipts are in. And they run straight through Hip Hop.
So What Is This Tool, Exactly?
The Atlantic’s AI Watchdog was originally launched in 2025 to expose the books, research papers, and video media being used to train AI systems without creators’ knowledge. In June 2026, Reisner extended it to music — and what he found was staggering in scale.
The tool searches four specific datasets that Reisner tracked down through academic papers and AI research-sharing platforms. These were openly shared within the AI development community, downloaded thousands of times, and confirmed by Google and Stability AI — in published research papers — as data they actually used.
When you search your name in the tool, it tells you whether you appear in any of these four datasets and how many entries show up. It does not prove your music was used to train any specific model — companies may combine multiple datasets, filter content, or use proprietary collections that haven’t been surfaced yet. Reisner himself notes that a track’s absence from the database is not proof it wasn’t used. There are likely other datasets no one has found.
But your presence in a collection downloaded thousands of times by AI developers is not nothing. It’s a paper trail where there was none before. For the first time, any artist can get a concrete answer to a question the industry has been dodging for years.
Go check. We’ll be here when you get back.
The Four Datasets — And the One That Matters Most to Hip Hop
Here’s what’s actually in the tool.
LAION-DISCO-12M is the largest: over 12.6 million links to YouTube music tracks, assembled by LAION, a German nonprofit that also built the image training data used for Stability AI’s Stable Diffusion. Released in November 2024, labeled for academic research, and explicitly warned against commercial use — it had already been downloaded thousands of times by people with no such restrictions in mind. The collection was built by automated bot, starting from a seed list of artists, recursively following YouTube Music’s “fans might also like” recommendations outward across the entire platform until it had catalogued 12 million tracks. Played back-to-back at an average of four minutes per track, that collection alone would take 91 years to get through.
DISCO-10M and the Free Music Archive — the latter originally a radio station research project from New Jersey’s WFMU — round out the smaller entries.
Then there is Sleeping-DISCO-9M. This is the one that seems to hit our culture, and it’s the dataset that has been coming up consistently in Atlantic Watchdog searches.
Assembled by a loose research collective calling itself Sleeping AI and published to Hugging Face in June 2025, Sleeping-DISCO contains approximately 9 million songs. Unlike LAION-DISCO, which was essentially just YouTube links and sparse audio metadata, Sleeping-DISCO was engineered to go deeper. The collective built it by scraping Genius.com — using software specifically designed to bypass Cloudflare’s site protection — and extracting everything available: song titles, artist and album credits, producer credits, genre tags, release dates, label information, YouTube audio links, and lyric embeddings, across 169 languages and nearly a thousand genre categories.
The collective published an academic paper about the dataset on arXiv (2506.14293). In it, they describe their mission plainly: to build a dataset from “actual popular music and world-renowned artists,” because prior datasets “fail to reflect real-world music and its flavour.” They named Maluma, Maroon 5, and Shakira as examples of the kind of artists included. They positioned Sleeping-DISCO as the open-source version of what Big Tech labs had been building privately for years, and offered it to anyone who wanted to download it.
After The Atlantic’s investigation ran, the dataset was quietly pulled. The Sleeping AI website now carries a small notice: “Sleeping DISCO was taken down.” The rest of the site still solicits research partnerships and internship applications. The contact email is still live.
But it had already been downloaded. The models had already learned.
This Isn’t Abstract — It Already Got Into the Culture
If the dataset question still feels like something happening in a server room somewhere, cast your mind back to May 2024.
Comedian King Willonius, riffing on the Drake-Kendrick Lamar beef and Rick Ross’s joke that Drake had gotten a BBL, typed a prompt into Udio — an AI music generator founded by former Google DeepMind engineers — and out came “BBL Drizzy.” A fully AI-generated 1970s-soul parody mocking Drake. Vocals, melody, instrumentation, lyrics: all machine-generated.
Metro Boomin caught the track, didn’t know the source, and released “BBL DRIZZY BPM 150.mp3” as a beat challenge. It hit 3.4 million SoundCloud streams in a week. Drake eventually rapped over the instrumental on Sexyy Red’s “U My Everything” — making it the first mainstream Hip Hop release to sample an AI-generated song. Billboard called it “the first notable example of AI sampling in mainstream hip-hop music.”
The song worked because Udio had been trained on exactly the genre it was mimicking — classic Motown and soul textures, the foundational sampling palette of Hip Hop production. The model knew what that music felt like because it had ingested it at scale. Udio’s co-founder, asked by Billboard which specific works were used in training, said: “We can’t reveal the exact source of our training data… We train the model on good music just like how human musicians would listen to music.” He could not elaborate on the copyright situation.
Weeks after “BBL Drizzy” went viral, the RIAA filed suit against both Udio and Suno on behalf of Universal Music Group, Sony Music, and Warner Music Group — alleging mass infringement at an “almost unimaginable scale.” What the Atlantic’s investigation now makes clear is exactly what that scale looked like. The four searchable datasets are part of what those models consumed. And Sleeping-DISCO’s contents included the Genius archive that holds Hip Hop’s lyrical and cultural history in structured, machine-readable form.
The Genius Connection Is Bigger Than It Looks
For Hip Hop specifically, what Sleeping AI did on Genius deserves its own paragraph.
Genius isn’t just a lyrics site. It’s the most comprehensive archive of Hip Hop’s written tradition ever assembled — a living document where artists, fans, and scholars annotate verses, debate meanings, trace sample lineages, and build historical context around everything from Rakim’s internal rhyme schemes to the literary references buried in Kendrick’s verses. It is community knowledge, collectively maintained over decades.
The irony is not lost on anyone who’s been around long enough to remember: Genius itself built its early lyrics database by scraping the manually-sourced OHHLA (the Original Hip Hop Lyrics Archive), a move that didn’t exactly endear them to the community at the time.
Sleeping AI scraped Genius wholesale. Their paper describes it plainly: “We wrote a Python spider and scraper using the cloudscraper library to map the entire Genius website. Cloudscraper was used to bypass the Cloudflare protection and then we parsed the html using BeautifulSoup and extracted all the available data fields.” They collected over months specifically to avoid overloading the servers — careful, methodical, thorough.
What that gives a model trained on this data isn’t just sonic texture. It gives it cultural structure — the ability to understand Hip Hop not as undifferentiated sound but as a genre with subgenres, regional scenes, production lineages, and lyrical traditions. It tells the model the difference between boom bap and trap, between Memphis chopped-and-screwed and Detroit ratchet. That granularity is exactly what separates a convincing AI-generated Hip Hop track from generic noise. And it came from the archive the culture built for itself.
The paper does note that full lyrics and Genius annotations were withheld from the public version, as “exclusive rights are reserved for Genius.” But those were made available separately to verified academic institutions. The distinction matters less than it sounds: the rest of what was scraped — 9 million songs’ worth of metadata, genre structure, audio links, and production credits — is more than enough to map the geography of the genre in detail.
Who Got a Settlement, and Who Got Left Behind
The litigation that followed the RIAA’s 2024 filings has moved fast, and very unevenly.
Warner Music settled with Suno in November 2025. Universal Music Group settled with Udio in October 2025, announcing a joint AI music platform with per-generation royalties reportedly in the range of $0.002 to $0.005. Udio has since signed additional licensing deals with indie coalition Merlin and publisher Kobalt. Sony Music is the lone major still fighting in court — its fair-use cases against both companies are expected to produce a ruling in summer 2026 that could define the legal standard for the entire industry.
The question before Judge Saylor in Massachusetts is whether training an AI model on copyrighted recordings constitutes transformative fair use, or infringement. Suno says it’s fair use. Sony says it’s straightforward theft at industrial scale. Everyone is waiting.
But here’s the gap that none of those settlements address: the major-label deals cover major-label catalogs. The independent artist who distributes through DistroKid, the producer who uploads to Bandcamp, the rapper who put freestyles on SoundCloud — their recordings were scraped right alongside Sony’s and Warner’s. They are in Sleeping-DISCO. They show up in the Atlantic database. They got nothing from the settlements, and they have no seat at the licensing table.
The class-action lawsuit Nguyen v. Suno Inc., filed in November 2025 in Northern California, is trying to change that. It represents a proposed class of independent musicians and small-label artists. The complaint alleges Suno’s total training data included over 40 million tracks, at least 60% of which came from independent artists. Class membership is open. Several artist communities online have been compiling lists of attorneys and resources for anyone who finds their music in the database and wants to act on it.
A CISAC-commissioned study estimated that generative AI could consume 24% of music creators’ revenues by 2028 — a cumulative €10 billion loss (roughly $11.3 billion USD) between 2023 and 2028. At the individual level, the instrumental duo The American Dollar alleged in a separate May 2026 lawsuit that Suno had cut their licensing revenue by nearly 80% since the platform launched.
What You Can Do Right Now
The AI Watchdog tool at theatlantic.com is free. Type your name. Document what comes back — screenshot the results, note which datasets your tracks appear in and how many entries there are.
If you find your music in the database:
The class actions are the most accessible route for independent artists without major-label backing. Nguyen v. Suno is the lead U.S. case; attorneys are actively building the class. The Artist Rights Alliance and the Black Music Action Coalition both have resources and have been vocal advocates in this fight since 2024.
Keep your release history detailed: what you distributed, when, through which platforms, what metadata was publicly visible. The more specific, the more useful you’ll be to litigation efforts.
And keep an eye on the Sony ruling this summer. A finding against Suno on fair use would force every AI music company to either license training data or rebuild their models from scratch — which changes the negotiating position of every artist whose music was swept up in this.







